You can load the ETL into a Parquet file, and save the new file to a shared folder location. When the ETL is run, the data will be loaded into Parquet files in the given folder. Each table in the data flow is loaded into a separate Parquet file and the corresponding .crc file is generated for each of these. To use a Parquet file as a target, add the Parquet node from the Targets panel to the data flow.
Configure a Parquet Target
From the target's Properties panel, name the new database that will be created, and provide a pointer to a shared folder where the file will be located:
- Shared Folder Path: provide a pointer to a shared folder where the new database will be saved.
- Expression: create a dynamic PQL expression to point to the shared folder path.
- Automatic File Naming: assign table names as file names. Disable to manually provide file name, or create an expression to provide file names.
- If you add multiple tables, this option will be enabled by default.
- Add Date Time Folder: create a folder named according to the date and time at which the ETL is run, and save the database file inside this folder.
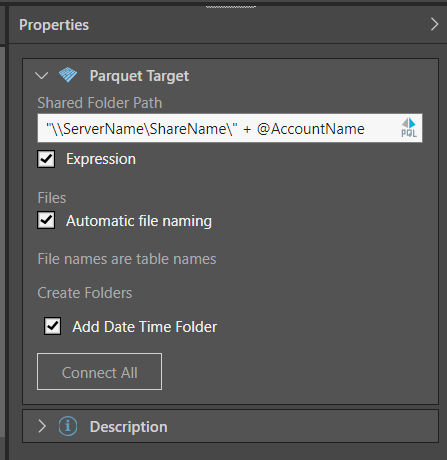
Finally, click 'Connect All' to connect the target node to the data flow. As usual, you can add a description to the node's Properties panel.
Description
Expand the Description window to add a description or notes to the node. The description is visible only from the Properties panel of the node, and does not produce any outputs. This is a useful way to document the ETL pipeline for yourself and other users.
Run the ETL
As there is no database or in-memory destination, the Data Model and Security stages are not relevant. Skip these steps and simply run the ETL from the Data Flow.
- Click here to learn how to process the ETL.
In this example, the ETL was loaded from an SQL server into an Parquet file. As seen in the Target properties (green highlight below) the Parquet target database was named 'Customers' and saved to a shared folder call DataModeling. Both Database Name and Date Time folders were enabled before connecting the tables to the target. The next step is to process the ETL.
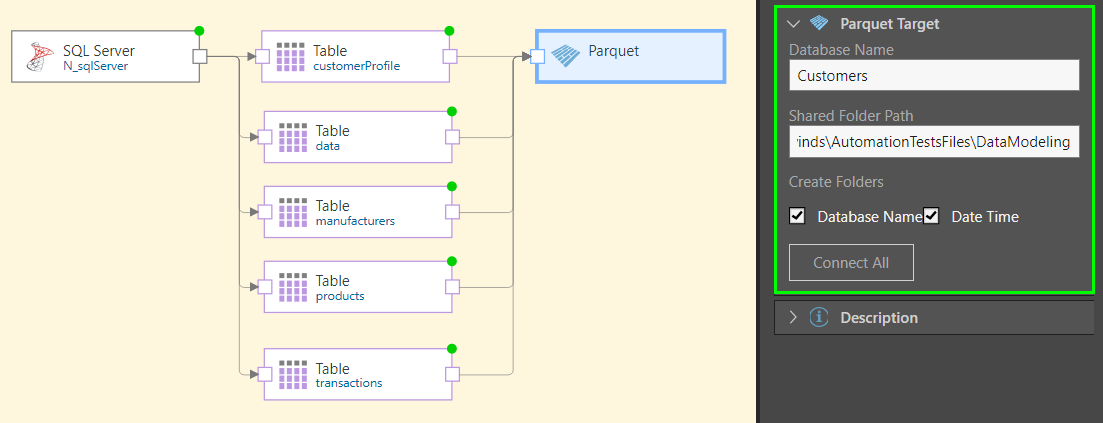
Once the ETL is executed, the Parquet file is saved to the given folder location, inside the Database Name folder and Date Time subfolder. Here we see the database folder 'Customers':
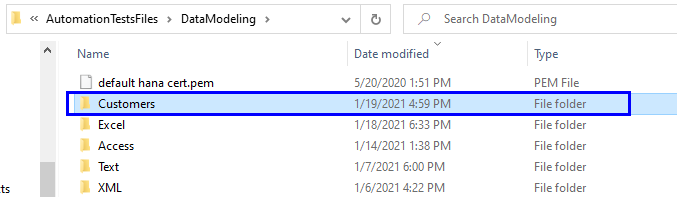
Inside the 'Customers' folder is the Date Time subfolder:

The Parquet database file is inside the Date Time subfolder. Each table in the ETL is loaded into a separate Parquet file, which is stored inside a table subfolder (subfolders named according to the table):
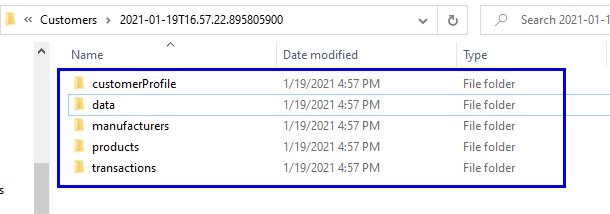
Inside each table folder is the table's Parquet file and the corresponding .crc file:
